gptransfer迁移工具把Greenplum数据库元数据和数据从一个Greenplum
数据库传输到另一个Greenplum数据库,允许用户迁移整个数据库的内容或者
选中的表到另一个数据库。源数据库和目标数据库可以在相同或者不同的集群
中。gptransfer在所有Segment间并行地移动数据,它使用gpfdist数据
装载工具以获得最高的传输率。
gptransfer会处理数据传输的设置和执行。参与其中的集群必须已经存在,
在两个集群的所有主机之间都有网络访问和证书认证的ssh访问(免密登陆)。
gptransfer接口包括传输一个或者更多完整数据库以及一个或者更多数据库
表的选项。一次完整数据库传输包括数据库模式、表数据、索引、视图、角
色、用户定义的函数以及资源队列。但包括postgres.conf和pg_hba.conf
在内的配置文件必须由管理员手工传输。用gppkg安装在数据库中的扩展(例
如 MADlib 和编程语言扩展)必须由管理员安装在目标数据库中。
gptransfer 会使用可写和可读外部表、Greenplum 的gpfdist并行数据装
载工具以及命名管道来从源数据库传输数据到目标数据库。源集群上的
Segment 从源数据库表中选择并且插入到一个可写外部表中。目标集群中的
Segment 从一个可读外部表选择并且插入到目标数据库表。可写和可读外部表
由源集群的 Segment 主机上的命名管道支撑,并且每个命名管道都有一个
gpfdist 进程负责把该管道的输出供应给目标 Segment 上的可读外部表。
gptransfer 通过以批次处理要被传输的数据库对象来编排其处理过程。对于每个要被传 输的表,它会执行下列任务:
- 在源数据库中创建一个可写外部表
- 在目标数据库中创建一个可读外部表
- 在源集群中的 Segment 主机上创建命名管道和 gpfdist 进程
- 在源数据库中执行一个 SELECT INTO 语句以插入源数据到可写外部表中
- 在目标数据库中执行一个 SELECT INTO 语句把数据从可读外部表插入到目标表中
- 可以选择通过在源和目标中比较行计数或者行的 MD5 哈希来验证数据
- 清除外部表、命名管道和 gpfdist
先决条件
- gptransfer 功能只能用于 Greenplum 数据库,包括 Dell EMC DCA appliance。不支持用 Pivotal HAWQ 作为源或者目的 源和目的 Greenplum 集群必须为
4.2 及以上版本。 - 至少一个 Greenplum 实例必须在其发布中包括有
gptransfer工具。该工具被包括在4.2.8.1 或更高版本以及 4.3.2.0 或更高版本的 Greenplum 数据库中。如果源或目标都不包括 gptransfer,用户必须升级其中一个集群以使用 gptransfer。 - 可以从源数据库或者目标数据库的集群中运行 gptransfer 工具。
- 目标集群中的
Segment数量必须大于等于源集群中主机的数量。目标中的 Segment 数量可以小于源中的 Segment 数量,但是数据将会以较低的速率被传输。 - 两个集群中的
Segment主机必须有网络连接彼此。 - 两个集群中的每一台主机必须能够用证书认证的
SSH连接到其他每一台主机。用户可以使用gpssh_exkeys工具在两个集群的主机之间交换公
快模式和慢模式
gptransfer使用gpfdist并行文件服务工具建立数据传输,后者会均匀地
把数据提供给目标 Segment。运行更多的gpfdist进程可以提高并行性和数
据传输率。当目标集群的 Segment 数量与源集群相同或者更多时,
gptransfer 会为每一个源 Segment 建立一个命名管道和一个 gpfdist 进
程。这是用于最优数据传输率的配置,并且被称为快模式
当目标集群中的Segment比源集群中少时,命名管道的输入端配置会有所不
同。gptransfer 会自动处理这种替代设置。配置中的不同意味着传输数据到
比源集群 Segment 少的目标集群比传输到具有和源集群同等或者更多
Segment 的目标集群更慢。它被称为慢模式,因为有较少的gpfdist进程将
数据提供给目标集群,不过每台 Segment 主机的那个 gpfdist 的传输仍然很
快。
当目标集群小于源集群时,每台 Segment 主机都有一个命名管道并且该主机上 的所有 Segment 都通过它发送数据。源主机上的 Segment 把它们的数据写到 连接着一个 gpfdist 进程的可写外部 Web 表,该进程同时也位于命名管道的 输入端。这会把表数据联合到一个单一命名管道中。该命名管道输出上的一个 gpfdist 进程会把这些联合起来的数据提供给目标集群。
在目标端,gptransfer 用源主机上的 gpfdist 定义一个可读外部表作为输 入,并且从这个可读外部表中选择数据到目标表中。这些数据会被均匀分布在 目标集群中的所有 Segment 上。
gptransfer
{ --full |
{ [-d database1 [ -d database2 ... ]] |
[-t db.schema.table [ -t db.schema1.table1 ... ]] |
[-f table-file [--partition-transfer
| --partition-transfer-non-partition-target ]]
[-T db.schema.table [ -T db.schema1.table1 ... ]]
[-F table-file] } }
[--skip-existing | --truncate | --drop]
[--analyze] [--validate=type] [-x] [--dry-run]
[--schema-only ]
[--source-host=source_host [--source-port=source_port]
[--source-user=source_user]]
[--base-port=base_gpfdist_port]
[--dest-host=dest_host --source-map-file=host_map_file
[--dest-port=port] [--dest-user=dest_user] ]
[--dest-database=dest_database_name]
[--batch-size=batch_size] [--sub-batch-size=sub_batch_size]
[--timeout=seconds]
[--max-line-length=length]
[--work-base-dir=work_dir] [-l log_dir]
[--format=[CSV|TEXT] ]
[--quote=character ]
[--no-final-count ]
[-v | --verbose]
[-q | --quiet]
[--gpfdist-verbose]
[--gpfdist-very-verbose]
[-a]
gptransfer --version
gptransfer -h | -? | --help
批尺寸和子批尺寸
一次gptransfer执行的并行度由两个命令行选项决定:--batch-size和--sub-batch-size。
–batch-size选项指定一批中传输的表数量。默认的批尺寸为2,这意味着任何时候都有两个表正在被传输。最小批尺寸为1,而最大值是10。
–sub-batch-size参数指定用于传输一个表的并行子进程的最大数目。默认值是25,并且最大值是50。批尺寸和子批尺寸的积就是并行量。
例如如果被设置为默认值,gptransfer可以执行50个并发任务。每个线程是一个Python进程并且会消耗内存,因此把这些值设置得太高可能会导致Python Out of Memory错误。
因此,在用户的环境下应该调整批尺寸。
为gptransfer准备主机
主机映射文件是一个文本文件,其中列出了源集群中的Segment主机。它被用来启用Greenplum集群中主机之间的通信。
该文件用--source-map-file=host_map_file命令选项在gptransfer命令行上指定。当使用gptransfer在两个单独的Greenplum集群之间拷贝数据时,它是一个必要选项。
host1_name,host1_ip_addr
host2_name,host2_ipaddr
...
限制
gptransfer只从用户数据库传输数据,postgres、template0以及template1数据库无法被传输。管理员必须手工传输配置文件并且用gppkg把扩展安装到目标数据库中。
目标集群必须具有至少和源集群Segment主机一样多的Segment。传输数据到一个较小的集群不如传输数据到较大的集群快。
传输小表或者空表无疑会比较慢。不管有没有实际的数据要传输,总是会有设置外部表以及Segment间并行数据装载的通信处理等固定开销。
完整模式和表模式
在使用–full选项运行时,gptransfer把源数据库中的所有表、视图、索引、角色、用户定义的函数和资源队列都拷贝到目标数据库中。要被传输的数据不能在目标集群上已经存在。
如果gptransfer在目标上找到该数据库,它将失败并且报出下面这样的消息:
[ERROR]:- gptransfer: error: --full option specified but tables exist on destination system
要单独拷贝表,可以使用-t命令行选项(一个表用一个选项)指定表或者使用-f命令行选项指定一个包含要传输表列表的文件。
表以完全限定的格式database.schema.table指定。表定义、索引和表数据会被拷贝。数据库必须在目标集群上已经存在。
如果用户尝试传输一个在目标数据库中已经存在的表,gptransfer默认会失败:
[INFO]:-Validating transfer table set...
[CRITICAL]:- gptransfer failed. (Reason='Table database.schema.table exists in database database .') exiting...
-
注意: 针对表存在问题,可以用
--skip-existing、--truncate或者--drop选项覆盖这一行为。 -
在完整模式和表模式中会被拷贝的对象:
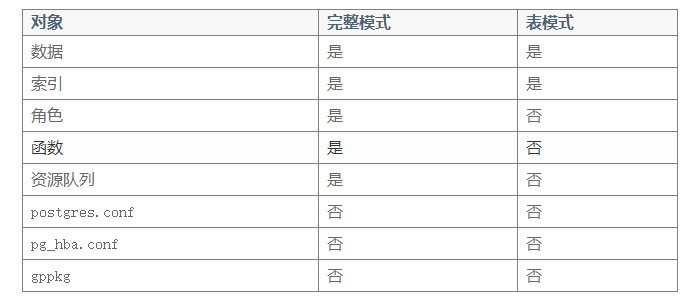
锁
-x选项启用表锁定。会在源表上放置一个排他锁直到拷贝以及验证(如果请求)完成。
验证
gptransfer默认不验证已传输的数据。用户可以使用--validate=type选项请求验证。验证类型可以是下列之一:
- count:比较源数据库和目标数据库中表的行计数。
- md5:在源和目标上都排序表,然后执行已排序行的逐行MD5哈希比较。
如果数据库在传输期间是可访问的,确保增加-x选项锁住表。否则,表可能在传输期间被更改,这会导致验证失败。
失败的传输
一个表上的失败不会结束gptransfer任务。当一个传输失败时,gptransfer会显示一个错误消息并且把表名加到一个失败传输文件中。
在gptransfer会话结束时,gptransfer会写出一个消息告诉用户有失败出现,并且提供失败传输文件的名称(在指令执行目录下有记录传输失败的文件记录表名)。例如:
[WARNING]:-Some tables failed to transfer. A list of these tables
[WARNING]:-has been written to the file failed_transfer_tables_20140808_101813.txt
[WARNING]:-This file can be used with the -f option to continue
最佳实践
gptransfer创建一个允许以非常高速率传输大量数据的配置。不过,对于小表或者空表,
gptransfer的设置和清除太过昂贵(固定开销导致传输小数据量时速度不理想)。最佳实践是对大型表使用gptransfer而用其他方法拷贝较小的表。
1、在用户开始传输数据之前,从源集群复制模式到目标集群。不要使用带–full –schema-only选项的gptransfer。这里有一些选项可以拷贝模式:
- 使用gpsd(Greenplum统计信息转储)支持工具。这种方法会包括统计信息,因此要确保在目标集群上创建模式之后运行ANALYZE。
- 使用PostgreSQL的pg_dump或者pg_dumpall工具,并且加上–schema-only选项。
- DDL脚本或者其他在目标数据库中重建模式的方法。
2、把要传输的非空表根据用户自己的选择划分成大型和小型两种类别。例如,用户可以决定大型表拥有超过1百万行或者原始数据尺寸超过1GB。
3、使用SQL的COPY命令为小型表传输数据。这可以消除使用gptransfer工具时在每个表上发生的预热/冷却时间。
可以选择编写或者重用现有的shell脚本来在要拷贝的表名列表上循环使用COPY命令。
4、使用gptransfer以表批次的方式传输大型表数据。
- 最好是传输到
相同尺寸的集群或者较大的集群,这样gptransfer会运行在快模式中。 - 如果存在
索引,在开始传输过程之前删除它们,避免在目标集群中持续创建索引,降低传输速度。 - 使用gptransfer的
表选项(-t)或者文件选项(-f)以批次执行迁移。不要使用完整模式运行gptransfer,模式和较小的表已经被传输过了。 - 在进行生产迁移之前,执行gptransfer处理的测试运行。这确保表可以被成功地传输。用户可以用
--batch-size和--sub-batch-size选项进行实验以获得最大的并行性。为gptransfer的迭代运行确定正确的表批次。 - 包括
--skip-existing选项,因为模式已经在目标集群上存在。 - 仅使用
完全限定的表名(database.schema.table)。注意表名中的句点(.)、空白、引号(’)以及双引号(”)可能会导致问题。 - 如果用户决定使用
--validation选项在传输后验证数据,确保也使用-x选项在源表上放置一个排他锁。
5、在所有的表都被传输后,执行下列任务:
- 检查并且改正失败的传输。
- 重新创建在传输前被删除的索引。
- 确保
角色、函数和资源队列在目标数据库中被创建。当用户使用gptransfer -t选项时,这些对象不会被传输。 - 从源集群拷贝
postgres.conf和pg_hba.conf配置文件到目标集群。 - 在目标数据库中用gppkg安装需要的扩展。
# -a:避免shell运行中还需要输入确认信息
nohup gptransfer
-t ztfxdb.ztfx.tb_sub_kw_stat
-t ztfxdb.ztfx.tb_sub_imp_stat
-t ztfxdb.ztfx.tb_sub_impkw_stat
--source-host=12.12.12.60 --source-map-file=source-map-file --dest-host=12.12.12.123 --drop -l /home/gpadmin/gptransferlog --batch-size=8 -a 1>/home/gpadmin/gptransferlog/000.log 2>&1 &