HiveThriftServer2是Spark基于HiveServer2实现的多Session管理的Thrift服务,提供对Hive的集中式管理服务。 HiveThriftServer2作为Yarn上的Application,目前只支持yarn-client模式——即Driver运行在本地, ApplicationMaster运行在NodeManager所管理的Container中。yarn-client模式相较于yarn-cluster模式, 在Driver和ApplicationMaster之间引入了额外的通信,因而服务的稳定性较低。
为了能够提高HiveThriftServer2的可用性,打算部署两个或者多个HiveThriftServer2实例, 最终确定了选择HA的解决方案。网上有关HiveThriftServer2的HA实现,主要借助了HAProxy、Nginx等提供的反向代理和负载均衡功能实现。 这种方案有个问题,那就是用户提交的执行SQL请求与HiveThriftServer2之间的连接一旦断了, 反向代理服务器并不会主动将请求重定向到其他节点上,用户必须再次发出请求,这时才会与其他HiveThriftServer2建立连接。 这种方案,究其根本更像是负载均衡,无法保证SQL请求不丢失、重连、Master/Slave切换等机制。
第三种方案
由于HiveThriftServer2本身继承自HiveServer2,所以HiveServer2自带的HA方案也能够支持HiveThriftServer2。 对于HiveServer2自带的HA方案不熟悉的同学,可以百度一下,相关内容还是很多的。如果按照我的假设, 就使用HiveServer2自带的HA方案的话,你会发现我的假设是错误的——HiveThriftServer2居然不支持HA。这是为什么呢? 请读者务必保持平常心,我们来一起研究研究。
HiveServer2的HA分析
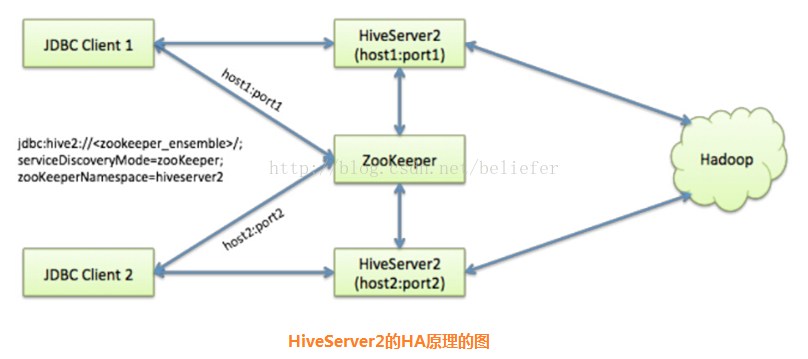
整个架构实际上围绕着ZooKeeper集群,利用ZooKeeper提供的创建节点、检索子节点等功能来实现。那么ZooKeeper的HA是如何实现的呢? 让我们来进行源码分析吧。
HiveServer2本身是由Java语言开发,熟悉Java应用(如Tomcat、Spark的Master和Worker、Yarn的ResourceManager和NodeManager等) 的同学应该知道,任何的Java应用必须要有一个main class。HiveServer2这个Thrift服务的main class就是HiveServer2类。 HiveServer2的main方法如代码清单1所示。
public static void main(String[] args) {
HiveConf.setLoadHiveServer2Config(true);
try {
ServerOptionsProcessor oproc = new ServerOptionsProcessor("hiveserver2");
ServerOptionsProcessorResponse oprocResponse = oproc.parse(args);
// 省略无关代码
// Call the executor which will execute the appropriate command based on the parsed options
oprocResponse.getServerOptionsExecutor().execute();
} catch (LogInitializationException e) {
LOG.error("Error initializing log: " + e.getMessage(), e);
System.exit(-1);
}
}
首先创建了ServerOptionsProcessor对象并对参数进行解析,parse方法解析完参数返回了oprocResponse对象 (类型为ServerOptionsProcessorResponse)。然后调用oprocResponse的getServerOptionsExecutor方法得到的对象 实际为StartOptionExecutor。最后调用了StartOptionExecutor的execute方法。StartOptionExecutor的实现见代码清单2。
static class StartOptionExecutor implements ServerOptionsExecutor {
@Override
public void execute() {
try {
startHiveServer2();
} catch (Throwable t) {
LOG.fatal("Error starting HiveServer2", t);
System.exit(-1);
}
}
}
StartOptionExecutor的execute方法实际调用了startHiveServer2方法,startHiveServer2方法中与HA相关的代码如下:
if (hiveConf.getBoolVar(ConfVars.HIVE_SERVER2_SUPPORT_DYNAMIC_SERVICE_DISCOVERY)) {
server.addServerInstanceToZooKeeper(hiveConf);
}
调用了HiveServer2的addServerInstanceToZooKeeper方法。这个addServerInstanceToZooKeeper的作用就是在指定的ZooKeeper集群上 创建持久化的父节点作为HA的命名空间,并创建持久化的节点将HiveServer2的实例信息保存到节点上(addServerInstanceToZooKeeper 方法的实现细节留给感兴趣的同学,自行阅读)。ZooKeeper集群如何指定?HA的命名空间又是什么?大家先记着这两个问题, 最后在配置的时候,再告诉大家。
HiveThriftServer2为何不支持HiveServer2自带的HA?
https://blog.csdn.net/beliefer/article/details/78549991