持久化机制
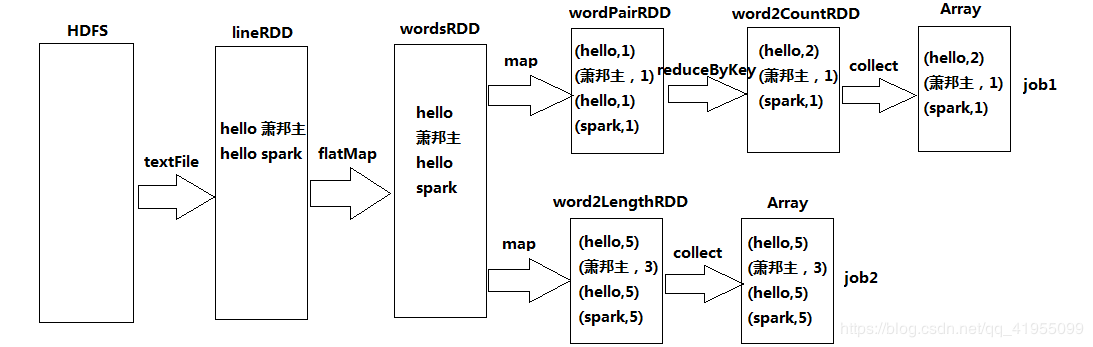
所谓RDD的持久化,其实就是对RDD进行缓存,它是Spark重要的优化手段之一。为什么需要对RDD进行缓存呢? 这与Spark作业的执行机制有关,我们知道,Spark程序只有遇到action算子的时候才会执行程序,具体的执行算法大致如下: Spark会以actionRDD为起点,根据RDD的依赖关系(血缘关系),向上寻找其父RDD,如果父RDD没有被缓存且该父RDD还存在着父RDD, 先把当前父RDD放入栈中,然后对当前父RDD继续递归调用该方法,直到找到有缓存的RDD或起点RDD(没有父RDD)才跳出递归, 然后一次运算栈中的RDD。由此算法不难看出如果某一个RDD被多次调用而没有被缓存,会触发多次Spark的job的执行,且每次都要从头开始运算, 以下一张RDD的依赖关系图足以说明这一点:
{kind=link}
不难发现wordsRDD被wordPairRDD和word2LengthRDD所依赖,当这个Spark程序执行时会因为有两个action算子而被拆分为两个job, job1和job2的执行都会按照上面的算法依次从HDFS中读取数据,然后算出lineRDD,再算出wordsRDD等等,不难发现会有重复的步骤, 特别是读取HDFS这一步会涉及到大量的磁盘IO,会严重影响程序的性能。因此如果将wordsRDD缓存后,当job2递归到wordsRDD后发现该RDD已经缓存则会跳出递归, 直接读取wordsRDD的值加以使用,使得程序很大程度得到优化。这就是RDD持久化的原理。
RDD的持久化机制的使用方法很简单,调用RDD.cache()或者RDD.persist(持久化级别)即可。实际上cache()方法底层就是调用persist()方法,其持久化级别参数为MEMORY_ONLY。
MEMORY_ONLY: 将RDD持久化至内存中,读取速度最快,但是会占用较多的内存空间MEMORY_ONLY_SER: 先将RDD的数据序列化再存入内存,内存占用会少一些,但是会耗费CPU对数据进行反序列化MEMORY_AND_DISK: 将数据优先存入内存,内存不足则存入硬盘MEMORY_AND_DISK_SER: 将数据序列化后优先存入内存,内存不足则存入硬盘DISK_ONLY: 将数据全部缓存进硬盘,性能最低
检查点机制Checkpoint
在复杂大型的Spark程序中,某些RDD可能被大量其他RDD所依赖,且重算该类RDD的代价很大,这时候就要考虑如何容错,即保证该类RDD的数据不丢失,用上面的持久化方法是不可取的,
原因是无论是何种的持久化级别数据仅仅存在节点的本地内存或者磁盘中,当节点挂掉时数据也随即丢失,因此需要一种更为可靠的方式进行RDD数据的容错,这就是RDD的CheckPoint机制。
Checkpoint机制要求用户首先输入一个可靠的CheckPoint目录路径,该路径用于存放要被存储的RDD数据,该路径必须是高可靠的共享文件系统,一般而言该路径在HDFS文件系统上。
CheckPoint的使用方法很简单,首先使用SparkContext的setCheckpointDir方法设置检查点目录,然后在要容错的RDD上调用RDD.checkpoint()。
- CheckPoint的底层工作原理
当某个RDD调用checkpoint()方法之后会接受RDDCheckpointData对象的管理,
RDDCheckpointData会把调用了checkpoint()方法的RDD的状态设置为MarkedForCheckpoint,
在执行job中调用最后一个RDD的doCheckpoint()方法,沿着RDD的血缘关系依次查找,
将标记为MarkedForCheckpoint的RDD的状态更改为CheckpointInProgress,然后单独启动一个job,
将血缘关系中标记为CheckpointInProgress的RDD的数据写入SparkContext.setCheckpointDir()方法设置的检查点目录里,
最后改变RDD的血缘关系,清除调用checkpoint()方法RDD的所有依赖,并将强行那些依赖的RDD的父RDD置为一个CheckpointRDD。
持久化与Checkpoint的区别
-
持久化仅把RDD的数据
缓存至本地内存或磁盘中,不具备高容错的能力;CheckPoint会把数据存储至SparkContext.setCheckpointDir()方法设置的检查点目录里,一般在高可用的共享文件系统上,具备容错的能力。 -
持久化仅仅缓存RDD的数据,不改变RDD的血缘关系;CheckPoint会强行改变RDD的血缘关系。
-
RDD的持久化机制与Checkpoint机制更多情况下会一起使用,为提升Spark程序的性能和高容错提供了非常好的方案。
-
切忌滥用RDD的持久化机制,如果频繁地使用RDD持久化可能会造成内存异常,磁盘IO时间过长等,在一定程度也是消耗系统资源。