背景
-
在Hadoop2.0中通常由两个NameNode组成,一个处于Active状态,另一个处于Standby状态。Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步Active NameNode的状态,以便能够在它失败时快速进行切换。
-
Hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM。我们使用简单的QJM。在该方案中,主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置大于或等于3奇数个JournalNode。
-
需要配置一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为Active状态。
-
Hadoop2.4之前的版本ResourceManager只有一个,仍然存在单点故障,Hadoop-2.4.1解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调。
基础软件安装
- JDK
- Zookeeper
- Hadoop
Hadoop(HDFS HA)总体架构
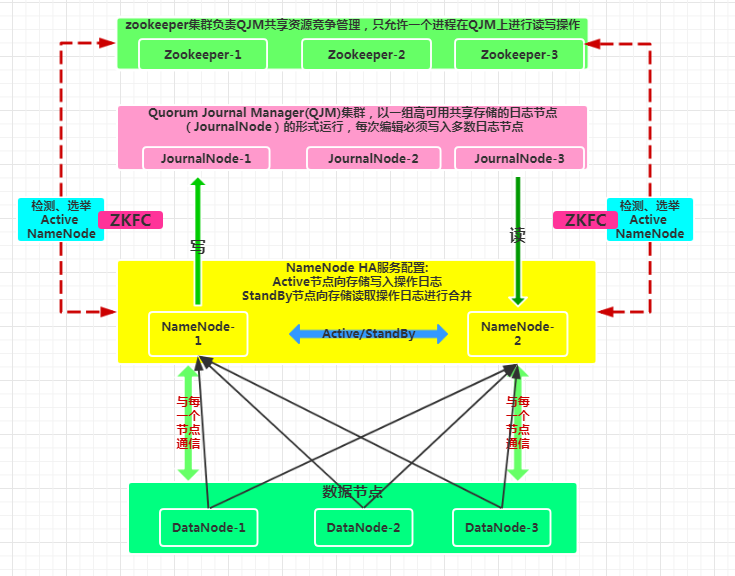
服务器分布及相关说明
集群信息规划分配如下:
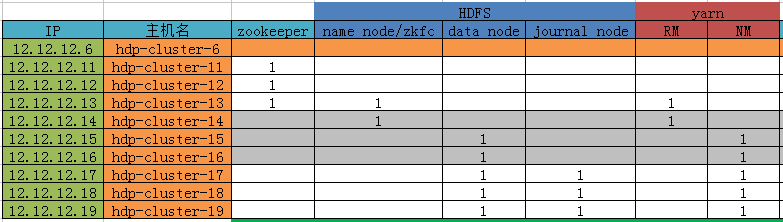
安装步骤
JDK安装
SSH免密登录
hosts配置
hdp-cluster-11
hdp-cluster-12
hdp-cluster-13
hdp-cluster-14
hdp-cluster-15
hdp-cluster-16
hdp-cluster-17
hdp-cluster-18
hdp-cluster-19
zookeeper集群搭建
Hadoop(HDFS HA)集群部署
环境变量设置
- 解压tar -xzvf hadoop-2.8.1.tar.gz
cd /root/hadoop-2.8.1/etc/hadoop配置hadoop-env.sh和yarn-env.sh的JAVA_HOME- slaves文件配置从节点(文件内容只要配置规划的
datanode节点即可)hdp-cluster-15
hdp-cluster-16
hdp-cluster-17
hdp-cluster-18
hdp-cluster-19
core-site.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://HdpCluster</value>
<final>true</final>
<description>The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.
</description>
</property>
<property>
<name>io.native.lib.available</name>
<value>false</value>
<description>Controls whether to use native libraries for bz2 and zlib
compression codecs or not. The property does not control any other native
libraries.
</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/BDS4/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>360</value>
<description>Number of minutes after which the checkpoint
gets deleted. If zero, the trash feature is disabled.
This option may be configured both on the server and the
client. If trash is disabled server side then the client
side configuration is checked. If trash is enabled on the
server side then the value configured on the server is
used and the client configuration value is ignored.
</description>
</property>
<!-- ha properties -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hdp-cluster-11:2181,hdp-cluster-12:2181,hdp-cluster-13:2181</value>
<description>
A list of ZooKeeper server addresses, separated by commas, that are
to be used by the ZKFailoverController in automatic failover.
</description>
</property>
<property>
<name>ha.zookeeper.parent-znode</name>
<value>/hadoop-ha</value>
<description>
The ZooKeeper znode under which the ZK failover controller stores
its information. Note that the nameservice ID is automatically
appended to this znode, so it is not normally necessary to
configure this, even in a federated environment.
</description>
</property>
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<!-- i/o properties -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
<description>The size of buffer for use in sequence files.
The size of this buffer should probably be a multiple of hardware
page size (4096 on Intel x86), and it determines how much data is
buffered during read and write operations.</description>
</property>
<property>
<name>io.serializations</name>
<value>org.apache.hadoop.io.serializer.WritableSerialization</value>
<description>A list of serialization classes that can be used for
obtaining serializers and deserializers.
org.apache.hadoop.io.serializer.avro.AvroSpecificSerialization, org.apache.hadoop.io.serializer.avro.AvroReflectSerialization
</description>
</property>
<!-- 配置用户代理 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>HdpCluster</value>
</property>
<!--name node存储数据目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/BDS1/hadoop/hdfs/namenode,/BDS2/hadoop/hdfs/namenode,/BDS3/hadoop/hdfs/namenode</value>
<final>true</final>
</property>
<!--data node存储数据目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/BDS1/hadoop/hdfs/datanode,/BDS2/hadoop/hdfs/datanode,/BDS3/hadoop/hdfs/datanode</value>
<final>true</final>
</property>
<!-- HdpCluster下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.HdpCluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.HdpCluster.nn1</name>
<value>hdp-cluster-13:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.HdpCluster.nn1</name>
<value>hdp-cluster-13:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.HdpCluster.nn2</name>
<value>hdp-cluster-14:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.HdpCluster.nn2</name>
<value>hdp-cluster-14:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hdp-cluster-17:8485;hdp-cluster-18:8485;hdp-cluster-19:8485/data</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/BDS4/journal/data</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.HdpCluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!--关闭权限认证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>
If "true", enable permission checking in HDFS.
If "false", permission checking is turned off,
but all other behavior is unchanged.
Switching from one parameter value to the other does not change the mode,
owner or group of files or directories.
</description>
</property>
<!--超级用户组 node存储数据目录 -->
<property>
<name>dfs.permissions.superusergroup</name>
<value>root</value>
</property>
<!--副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--最大副本数 -->
<property>
<name>dfs.replication.max</name>
<value>50</value>
</property>
<!--支持文件内容追加 -->
<property>
<name>dfs.support.append</name>
<value>true</value>
<final>true</final>
</property>
<!--web服务端访问开启 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<final>true</final>
</property>
<!--data node 默认文件目录权限 -->
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>750</value>
</property>
<!--容忍坏盘个数(N-1) -->
<property>
<name>dfs.datanode.failed.volumes.tolerated</name>
<value>1</value>
<final>true</final>
</property>
</configuration>
mapred-site.xml 配置
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<!-- 指定mr框架为yarn方式(local/yarn) -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 关闭推测执行 网上反馈有问题,待验证-->
<property>
<name>mapreduce.map.speculative</name>
<value>false</value>
</property>
<property>
<name>mapreduce.reduce.speculative</name>
<value>false</value>
</property>
<property>
<name>mapreduce.cluster.temp.dir</name>
<value>/BDS4/mapred/temp</value>
</property>
<!-- application应用提交时上传文件的副本数,可以加快map启动-->
<property>
<name>mapreduce.client.submit.file.replication</name>
<value>5</value>
</property>
<!-- 最多能申请的counter数量 -->
<property>
<name>mapreduce.job.counters.max</name>
<value>10</value>
</property>
<!-- 当只有一个reduce任务的计算时,启用uber模式,直接在AppMaster进行运算 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>false</value>
</property>
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
<property>
<name>mapreduce.job.ubertask.maxbytes</name>
<value/>
</property>
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>2</value>
</property>
<property>
<!-- 当启用了强制本地执行策略,该配置将告知是否遵循严格的数据本地化。如果启用,重用容器只能被分配至本节点上的任务。 -->
<name>mapreduce.container.reuse.enforce.strict-locality</name>
<value>false</value>
</property>
<property>
<name>mapreduce.job.maxtaskfailures.per.tracker</name>
<value>3</value>
</property>
<!-- reduce进行shuffle的时候,用于启动合并输出和磁盘溢写的过程的阀值,默认为0.66。如果允许,适当增大其比例能够减少磁盘溢写次数,提高系统性能。同mapreduce.reduce.shuffle.input.buffer.percent一起使用。 -->
<property>
<name>mapreduce.reduce.shuffle.merge.percent</name>
<value>0.8</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/BDS4/yarn/staging</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/BDS4/mr-history/tmp</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/BDS4/mr-history/done</value>
</property>
<!-- YarnChild 启动JVM参数设置-->
<property>
<name>mapred.child.java.opts</name>
<value>-Xms1024M -Xmx2048M -Xloggc:/tmp/@taskid@.gc</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1024M -Djava.net.preferIPv4Stack=true</value>
</property>
<property>
<name>mapreduce.admin.map.child.java.opts</name>
<value>-Dzookeeper.request.timeout=120000 -server -XX:NewRatio=8 -Djava.net.preferIPv4Stack=true</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1536</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx1024M -Djava.net.preferIPv4Stack=true</value>
</property>
<property>
<name>mapreduce.admin.reduce.child.java.opts</name>
<value>-Dzookeeper.request.timeout=120000 -server -XX:NewRatio=8 -Djava.net.preferIPv4Stack=true</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx1024m -XX:CMSFullGCsBeforeCompaction=1 -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -verbose:gc</value>
</property>
<!-- 配置历史服务-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hdp-cluster-14:10020</value>
<description>MapReduce JobHistory Server IPC host:port</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hdp-cluster-14:19888</value>
<description>MapReduce JobHistory Server Web UI host:port</description>
</property>
</configuration>
yarn-site.xml 配置
<?xml version="1.0"?>
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>hdpcompute</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hdp-cluster-13</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hdp-cluster-14</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hdp-cluster-11:2181,hdp-cluster-12:2181,hdp-cluster-13:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<description>
当设置yarn.nodemanager.resource.detect-hardware-capabilities为true时,系统会自动计算,否则默认值为8192MB.
</description>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<description>虚拟内核数设置,默认值8</description>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
</configuration>
启动过程
启动zookeeper集群
启动journal node节点
(首次初始化数据目录需要提前启动)
三台机器上分别启动journalnode(类似于ZK) : ./sbin/hadoop-daemon.sh start journalnode,并jps查看进程,显示 JournalNode
格式化namenode
在任意一个namenode节点上:./bin/hdfs namenode -format,成功后将所初始化的元数据信息拷贝到另一个namenode节点上。
或者
成功启动改namenode之后在另一个节点执行./bin/hdfs namenode -bootstrapStandby同步元数据,在启动该节点namenode进程,
./sbin/hadoop-daemon.sh start namenode.
格式化ZKFC
./bin/hdfs zkfc -formatZK
启动主NameNode
./sbin/start-dfs.sh(能远程控制相关服务(zkfc、journal node)启动)-
./sbin/hadoop-daemon.sh start namenode(属于启动单个进程) - 在备NameNode从master同步到slave1
./bin/hdfs namenode -bootstrapstandby,同步文件镜像 -
启动备NameNode
./sbin/hadoop-daemon.sh start namenode -
在两个NameNode节点(master、slave)上执行
./sbin/hadoop-daemon.sh start zkfc -
启动所有的DataNode节点
./sbin/hadoop-daemon.sh start datanode -
启动Yarn 启动yarn的脚步不能同时启动两个resourcemanager。
./sbin/start-yarn.sh
./sbin/yarn-daemons.sh start resourcemanager -
HDFS的HA功能测试 http://hdp-cluster-13:50070/dfshealth.html
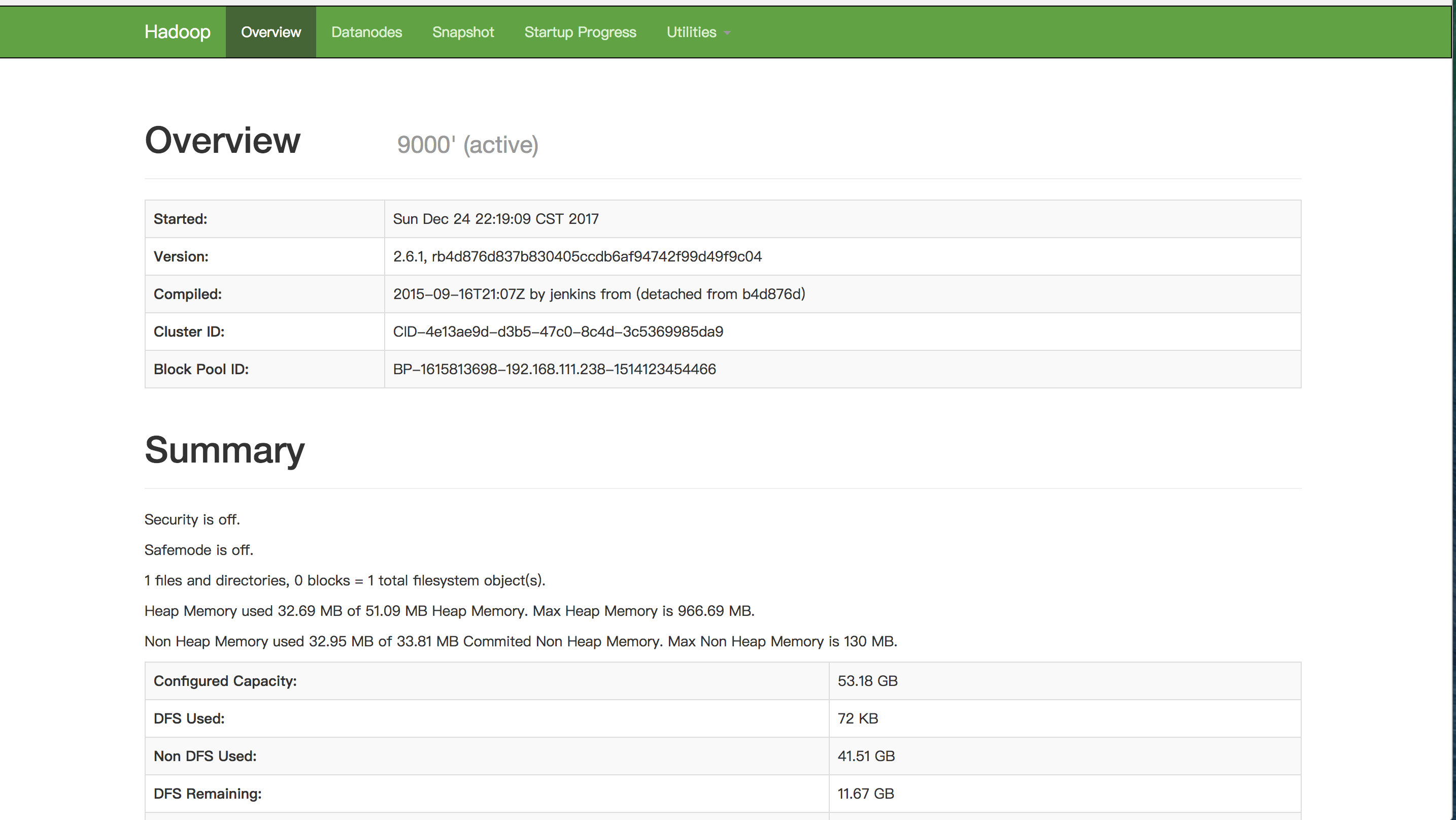
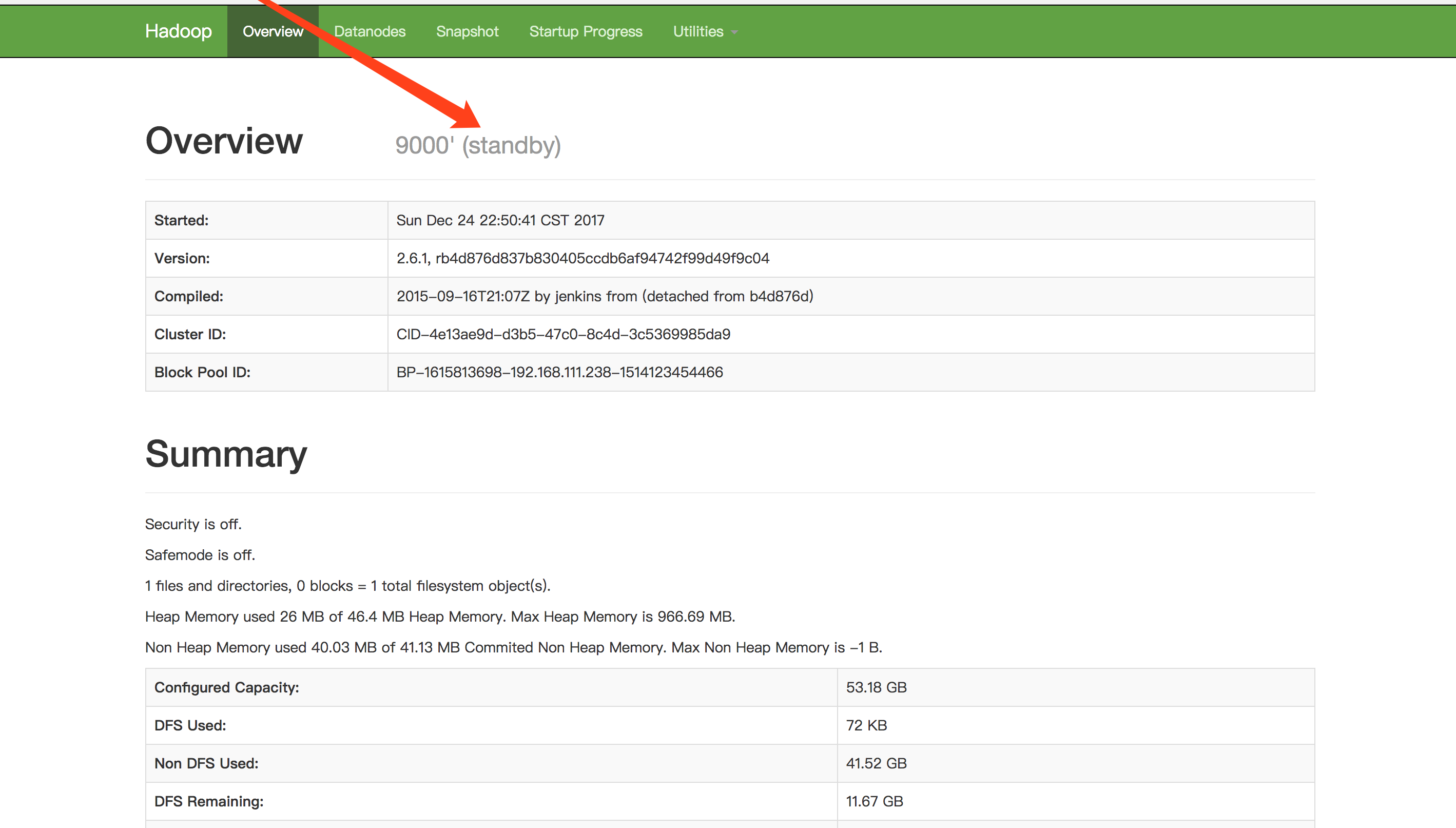
- 将主节点上的NameNode kill 后,再次重启查看页面效果。通过命令
jps查看主NameNode进程,然后kill -9 进程号,现次重启刚刚kill的NameNode, 分别访问http://hdp-cluster-13:50070/dfshealth.html和http://hdp-cluster-14:50070/dfshealth.html查看状态是否已经切换。
上传文件测试
- 列出服务器上/目录下的文件
./bin/hadoop fs -ls /,最初什么也没有。 - 将本地文件上传到 / 进行测试
./bin/hadoop fs -put /etc/passwd /,再用上面的命令进行查看,显示出刚上传的文件。 -
查看文件内容
./bin/hadoop fs -text /passwd,可以显示文件中的所有内容。 - 通过 Web 界面查看任务的运行情况
http://hdp-cluster-13:8088/cluster
不停机更新配置
对集群配置文件修改后,将文件同步到各节点执行如下命令分别将信息更新到namenode和 resourcemananger上
# 具体使用查看帮助文档
hdfs dfsadmin –refreshSuperUserGroupsConfiguration
yarn rmadmin –refreshSuperUserGroupsConfiguration