Flume高可用
在完成单点的Flume NG搭建后,下面我们搭建一个高可用的Flume NG集群,架构图如下所示:
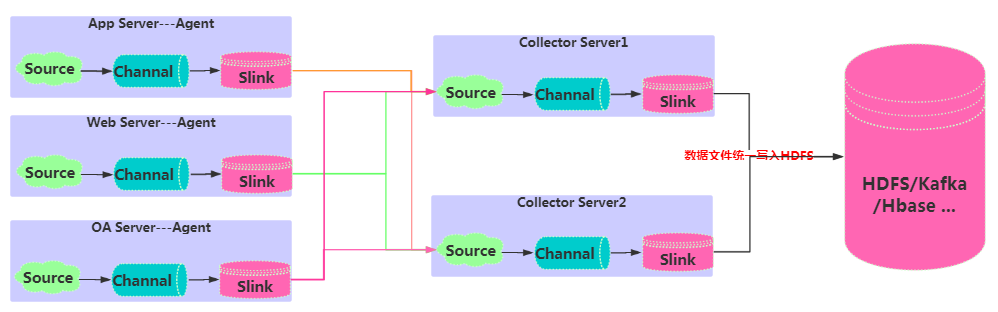
主要能实现高可用部分是:Flume聚合各个agent采集的数据,统一写入到HDFS/Kafka/Hbase等目标库。
- 规划部署
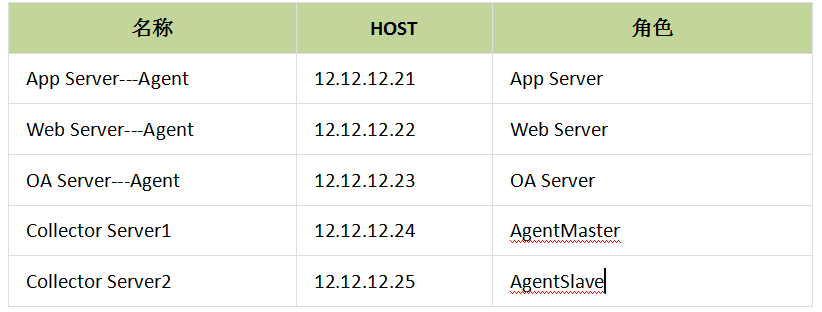
- 配置文件
Agent配置终端数据采集,保证采集的数据作
failover控制
#agent1 name
agent1.channels = c1
agent1.sources = r1
agent1.sinks = k1 k2
#set channel
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 1000 #channel中存储 events 的最大数量
agent1.channels.c1.transactionCapacity = 100 #事物容量,不能大于capacity,不能小于batchSize
agent1.sources.r1.type = spooldir #spooldir类型
agent1.sources.r1.spoolDir = /data/logdfs #此路径下每产生新文件,flume就会自动采集
agent1.sources.r1.fileHeader = true
agent1.sources.r1.channels = c1
# set sink1
agent1.sinks.k1.channel = c1
agent1.sinks.k1.type = avro
agent1.sinks.k1.hostname = node04
agent1.sinks.k1.port = 52020
# set sink2
agent1.sinks.k2.channel = c1
agent1.sinks.k2.type = avro #协议类型
agent1.sinks.k2.hostname = node05
agent1.sinks.k2.port = 52020
#set gruop
agent1.sinkgroups = g1
#set sink group
agent1.sinkgroups.g1.sinks = k1 k2
#set failover
agent1.sinkgroups.g1.processor.type = failover #故障转移,若node04故障,node05自动接替node04工作
agent1.sinkgroups.g1.processor.priority.k1 = 10 #优先级10
agent1.sinkgroups.g1.processor.priority.k2 = 5 #优先级5
agent1.sinkgroups.g1.processor.maxpenalty = 10000 #最长等待10秒转移故障
Collector配置:
a1.sources = r1
a1.channels = kafka_c1 hdfs_c2
a1.sinks = kafka_k1 hdfs_k2
#properties of avro-AppSrv-source
a1.sources.r1.type = avro
a1.sources.r1.bind = node04
a1.sources.r1.port = 52020
a1.sources.r1.channels=kafka_c1 hdfs_c2 #设置sources的channels
#增加拦截器 所有events,增加头,类似json格式里的"headers":{" key":" value"}
a1.sources.r1.interceptors = i1 #拦截器名字
a1.sources.r1.interceptors.i1.type = static #拦截器类型
a1.sources.r1.interceptors.i1.key = Collector #自定义
a1.sources.r1.interceptors.i1.value = node04 #自定义
#set kafka channel
a1.channels.kafka_c1.type = memory
a1.channels.kafka_c1.capacity = 1000
a1.channels.kafka_c1.transactionCapacity = 100
#set hdfs channel
a1.channels.hdfs_c2.type = memory
a1.channels.hdfs_c2.capacity = 1000
a1.channels.hdfs_c2.transactionCapacity = 100
#set sink to kafka
a1.sinks.kafka_k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.kafka_k1.channel=kafka_c1 #传输的channel名
a1.sinks.kafka_k1.topic = rwb_topic #kafka中的topic
a1.sinks.kafka_k1.brokerList = 12.12.12.3:9092,12.12.12.4:9092,12.12.12.4:9092
a1.sinks.kafka_k1.requiredAcks = 1
a1.sinks.kafka_k1.batchSize = 1000
#set sink to hdfs
a1.sinks.hdfs_k2.type=hdfs #传输到hdfs
a1.sinks.hdfs_k2.channel=hdfs_c2 #传输的channel名
a1.sinks.hdfs_k2.hdfs.path=hdfs://12.12.12.3:9000/flume/logdfs #这里hadoop集群时HA集群,所以这里写的是集群的Namespace
a1.sinks.hdfs_k2.hdfs.fileType=DataStream
a1.sinks.hdfs_k2.hdfs.writeFormat=TEXT #文本格式
a1.sinks.hdfs_k2.hdfs.rollInterval=1 #失败1s回滚
a1.sinks.hdfs_k2.hdfs.filePrefix=%Y-%m-%d #文件名前缀
a1.sinks.hdfs_k2.hdfs.fileSuffix=.txt #文件名后缀
a1.sinks.hdfs_k2.hdfs.useLocalTimeStamp = true
Flume监控
flume提供了一个度量框架,可以通过http的方式进行展现,当启动agent的时候通过传递参数 -Dflume.monitoring.type=http参数给flume agent:
./bin/flume-ng agent
--conf ./conf \
--conf-file ./conf/netcat.conf \
-name agentNetCat \
-Dflume.root.logger=INFO,console \
-Dflume.monitoring.type=http \
-Dflume.monitoring.port=5653 \
-Dflume.root.logger=INFO,console
这样flume会在5653端口上启动一个HTTP服务器,访问 http://12.12.12.3:5653/metrics地址,将返回JSON格式的flume相关指标参数:
{
"SOURCE.src-1":{
"OpenConnectionCount":"0", //目前与客户端或sink保持连接的总数量(目前只有avro source展现该度量)
"Type":"SOURCE",
"AppendBatchAcceptedCount":"1355", //成功提交到channel的批次的总数量
"AppendBatchReceivedCount":"1355", //接收到事件批次的总数量
"EventAcceptedCount":"28286", //成功写出到channel的事件总数量,且source返回success给创建事件的sink或RPC客户端系统
"AppendReceivedCount":"0", //每批只有一个事件的事件总数量(与RPC调用中的一个append调用相等)
"StopTime":"0", //source停止时自Epoch以来的毫秒值时间
"StartTime":"1442566410435", //source启动时自Epoch以来的毫秒值时间
"EventReceivedCount":"28286", //目前为止source已经接收到的事件总数量
"AppendAcceptedCount":"0" //单独传入的事件到Channel且成功返回的事件总数量
},
"CHANNEL.ch-1":{
"EventPutSuccessCount":"28286", //成功写入channel且提交的事件总数量
"ChannelFillPercentage":"0.0", //channel满时的百分比
"Type":"CHANNEL",
"StopTime":"0", //channel停止时自Epoch以来的毫秒值时间
"EventPutAttemptCount":"28286", //Source尝试写入Channe的事件总数量
"ChannelSize":"0", //目前channel中事件的总数量
"StartTime":"1442566410326", //channel启动时自Epoch以来的毫秒值时间
"EventTakeSuccessCount":"28286", //sink成功读取的事件的总数量
"ChannelCapacity":"1000000", //channel的容量
"EventTakeAttemptCount":"313734329512" //sink尝试从channel拉取事件的总数量。这不意味着每次事件都被返回,因为sink拉取的时候channel可能没有任何数据
},
"SINK.sink-1":{
"Type":"SINK",
"ConnectionClosedCount":"0", //下一阶段或存储系统关闭的连接数量(如在HDFS中关闭一个文件)
"EventDrainSuccessCount":"28286", //sink成功写出到存储的事件总数量
"KafkaEventSendTimer":"482493",
"BatchCompleteCount":"0", //与最大批量尺寸相等的批量的数量
"ConnectionFailedCount":"0", //下一阶段或存储系统由于错误关闭的连接数量(如HDFS上一个新创建的文件因为超时而关闭)
"EventDrainAttemptCount":"0", //sink尝试写出到存储的事件总数量
"ConnectionCreatedCount":"0", //下一个阶段或存储系统创建的连接数量(如HDFS创建一个新文件)
"BatchEmptyCount":"0", //空的批量的数量,如果数量很大表示souce写数据比sink清理数据慢速度慢很多
"StopTime":"0",
"RollbackCount":"9", //
"StartTime":"1442566411897",
"BatchUnderflowCount":"0" //比sink配置使用的最大批量尺寸更小的批量的数量,如果该值很高也表示sink比souce更快
}
}
自定义Flume组件
Flume本身可插拔的架构设计,使得开发自定义插件变得很容易。Flume本身提供了非常丰富的source、channel、sink以及拦截器等插件可供选择,基本可以满足生产需要。
- plugins.d目录
plugins.d(
$FLUME_HOME/目录下新增)是flume事先约定的存放自定义组件的目录。flume在启动的时候会自动将该目录下的文件添加到classpath下,当然你也可以在flume-ng 启动时通过指定–classpath,-C参数将自己的文件手动添加到classpath下。相关目录说明:
plugins.d/xxx/lib - 插件jar
plugins.d/xxx/libext - 插件依赖jar
plugins.d/xxx/native - 本地库文件如 .so文件;
Flume自定义拦截器
拦截器(Interceptor)是简单插件式组件,设置在Source和Source写入数据的Channel之间。Source接收到的事件在写入对应的Channel之前,拦截器都可以转换或删除这些事件。
每个拦截器实例只处理同一个Source接收的事件。拦截器可以基于任意标准删除或转换事件,但是拦截器必须返回尽可能多(尽可能少)的事件,
如同原始传递过来的事件.因为拦截器必须在事件写入Channel之前完成操作,只有当拦截器已成功转换事件后,RPC Source(和任何其他可能产生超时的Source)才会响应发送事件的客户端或Sink。
因此尽量不要在拦截器中做大量耗时的处理操作。如果不得已这么处理了,那么需要相应的调整超时时间属性。Flume自身提供了多种类型的拦截器,
比如:时间戳拦截器、主机拦截器、正则过滤拦截器等等。
拦截器一般用于分析事件以及在需要的时候丢弃事件。编写拦截器时,实现者只需要写以一个实现Interceptor接口的类,
同时实现Interceptor$Builder接口的Builer类。所有的Builder类必须有一个公共无参的构造方法,Flume使用该方法来进行实例化。
可以使用传递到Builder类的Context实例配置拦截器。所有需要的参数都要传递到Context实例。
public class TimestampInterceptor implements Interceptor {
private final boolean preserveExisting;
/**
* 该构造方法只能被Builder调用
*/
private TimestampInterceptor(boolean preserveExisting) {
this.preserveExisting = preserveExisting;
}
@Override
public void initialize() {
// no-op
}
/**
* Modifies events in-place.
*/
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
if (preserveExisting && headers.containsKey(TIMESTAMP)) {
// we must preserve the existing timestamp
} else {
long now = System.currentTimeMillis();
headers.put(TIMESTAMP, Long.toString(now));
}
return event;
}
/**
* Delegates to {@link #intercept(Event)} in a loop.
* @param events
* @return
*/
@Override
public List<Event> intercept(List<Event> events) {
for (Event event : events) {
intercept(event);
}
return events;
}
@Override
public void close() {
// no-op
}
/**
* Builder which builds new instances of the TimestampInterceptor.
*/
public static class Builder implements Interceptor.Builder {
private boolean preserveExisting = PRESERVE_DFLT;
@Override
public Interceptor build() {
return new TimestampInterceptor(preserveExisting);
}
//通过Context传递配置参数
@Override
public void configure(Context context) {
preserveExisting = context.getBoolean(PRESERVE, PRESERVE_DFLT);
}
}
public static class Constants {
public static String TIMESTAMP = "timestamp";
public static String PRESERVE = "preserveExisting";
public static boolean PRESERVE_DFLT = false;
}
}
- intercept()的两个方法必须是线程安全的,因为如果source运行在多线程情况下,这些方法可能会被多个线程调用。
- 自定义拦截器的配置方式,interceptors type配置的是XXXInterceptor$Builder:
#自定义拦截器 --producer agent名称 --src-1 source名称 —-i1 拦截器名称
producer.sources.src-1.interceptors = i1
producer.sources.src-1.interceptors.i1.type = com.networkbench.browser.flume.interceptor.MyBrowserInterceptor$Builder
- 将自定义代码打包放置到前面的plugins.d/ext-interceptors(可以自己命名)/lib目录下,启动flume时会自动加载该jar到classpath