Avro Files、ORC、RCFile、Parquet、SequenceFile等属于文件储存的一种格式,其已经默认包含了文件压缩算法,如LZO、Gzip等。
在某些情况下,将压缩的数据保存在Hive表中比未压缩存储的性能更好;无论是在磁盘使用方面还是在查询性能方面。
可以将压缩了Gzip或Bzip2的文本文件直接导入到存储为TextFile的表中。压缩会被自动检测,并且在查询执行期间,
文件将在运行时被动态解压缩。但对于不可分片的文件压缩会导致运行的MAP任务数少,运行慢,效率低
LZO压缩
LZO是一个无损的数据压缩库,相比于压缩比它更加追求速度。 需要在Hadoop集群中每个节点里安装lzo和lzop。
core-site.xml配置支持LZO压缩:
<property>
<name>io.compression.codecs</name>
<value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,com.hadoop.compression.lzo.LzoCodec,com.hadoop.compression.lzo.LzopCodec</value>
</property>
<property>
<name>io.compression.codec.lzo.class</name>
<value>com.hadoop.compression.lzo.LzoCodec</value>
</property>
- hive配置使用
SET hive.exec.compress.output=true
SET mapreduce.output.fileoutputformat.compress=true
mapreduce.output.fileoutputformat.compress.type=BLOCK
SET mapreduce.output.fileoutputformat.compress.codec=com.hadoop.compression.lzo.LzoCodec
ORC存储格式
ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初, 最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。和Parquet类似,它并不是一个单纯的列式存储格式, 仍然是首先根据行组分割整个表,在每一个行组内进行按列存储。ORC文件是自描述的,它的元数据使用Protocol Buffers序列化, 并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被Spark SQL、Presto等查询引擎支持,但是Impala对于ORC目前没有支持, 仍然使用Parquet作为主要的列式存储格式。2015年ORC项目被Apache项目基金会提升为Apache顶级项目。ORC具有以下一些优势:
- ORC是列式存储,有多种文件压缩方式,并且有着很高的压缩比。
- 文件是可切分(Split)的。因此,在Hive中使用ORC作为表的文件存储格式,不仅节省HDFS存储资源,查询任务的输入数据量减少,使用的MapTask也就减少了。
- 提供了多种索引,
row group index、bloom filter index。 - ORC可以支持复杂的数据结构(比如Map等)
列式存储
由于OLAP查询的特点,列式存储可以提升其查询性能。相对于关系数据库中通常使用的行式存储, 在使用列式存储时每一列的所有元素都是顺序存储的。由此特点可以给查询带来如下的优化:
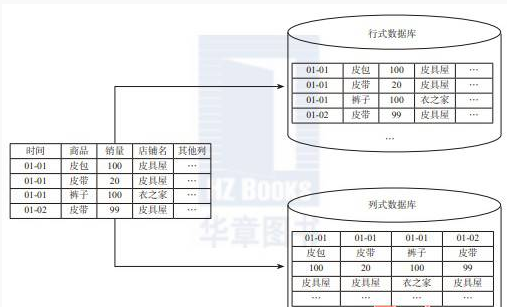
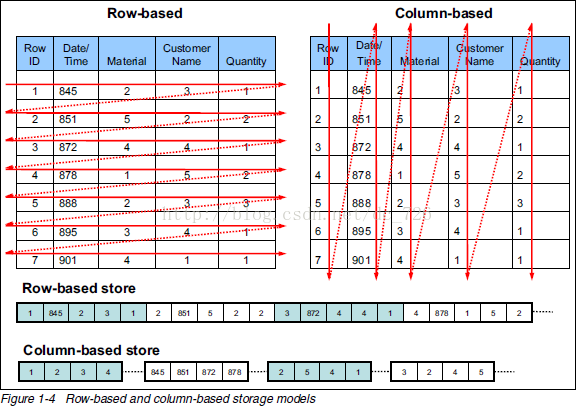
- 查询的时候不需要扫描全部的数据,而只需要读取每次查询涉及的列,这样可以将I/O消耗降低N倍, 另外可以保存每一列的统计信息(min、max、sum等),实现部分的谓词下推。
- 由于每一列的成员都是同构的,可以针对不同的数据类型使用更高效的数据压缩算法,进一步减小I/O。
- 由于每一列的成员的同构性,可以使用更加适合CPU pipeline的编码方式,减小CPU的缓存失效。
Optimized Row Columnar(ORC)文件格式提供了存储Hive数据的高效方法。它的设计是为了克服其他Hive文件格式的限制。 使用ORC文件可以提高Hive在读取、写入和处理数据时的性能。
与RCFile格式相比,ORC文件格式有很多优点:
(1)、每个task只输出单个文件,这样可以减少NameNode的负载; (2)、支持各种复杂的数据类型,比如: datetime, decimal, 以及一些复杂类型(struct, list, map, and union); (3)、在文件中存储了一些轻量级的索引数据; (4)、基于数据类型的块模式压缩:a、integer类型的列用行程长度编码(run-length encoding);b、String类型的列用字典编码(dictionary encoding); (5)、用多个互相独立的RecordReaders并行读相同的文件; (6)、无需扫描markers就可以分割文件; (7)、绑定读写所需要的内存; (8)、metadata的存储是用 Protocol Buffers的,所以它支持添加和删除一些列。
文件结构
ORC文件包含称为stripes的行数据组,以及文件页脚中的辅助信息。在文件的末尾,一个postscript保存了压缩参数和压缩页脚的大小。
默认的脚本大小为250MB。大的stripes可以大块的高效的从HDFS上读取。
文件页脚包含文件中的stripes列表、每个stripes的行数和每列的数据类型。它还包含列级的聚合计数、最小值、最大值和总和。
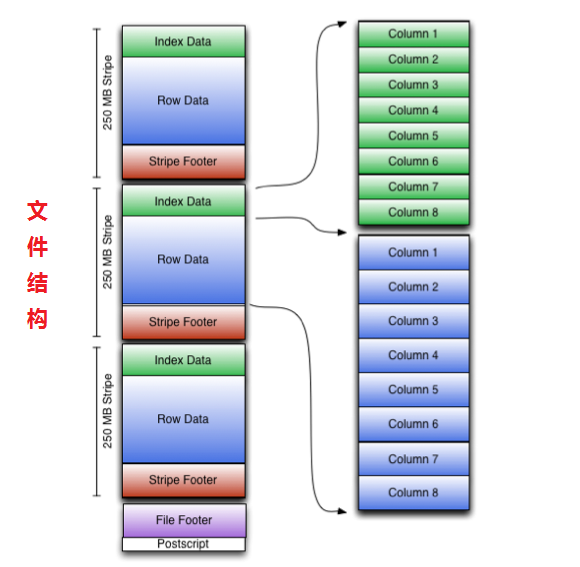
- Stripe 结构
- stripe footer包含一个流位置目录
- Row data用于表扫描。
- Index data包括每个列的最小值和最大值,以及每个列中的行位置。 (还可能包含一些字段或bloom过滤器。) 行索引项提供了偏移量可以找到正确的压缩块和在解压缩块后的字节。 注意,ORC索引仅用于选择stripe footer和Row data,而不用于相应查询。
HiveQL语法
# 三种方式
# 建表时指定文件格式
CREATE TABLE ... STORED AS ORC
# 修改表文件格式
ALTER TABLE ... [PARTITION partition_spec] SET FILEFORMAT ORC
# 全局设置hive格式
SET hive.default.fileformat=orc
- tblproperties的参数信息
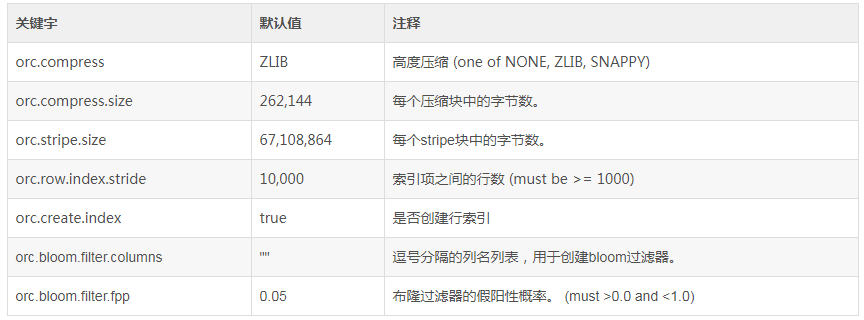
# 创建一个没有使用压缩的ORC表
create table tb_address (
name string,
street string,
city string,
state string,
zip int
) stored as orc tblproperties ("orc.compress"="NONE");